Homework on probability
In this homework we are going to revisit some concept that we covered in class.
Analytical questions
Question 1: Suppose we toss a fair coin until we get exactly two heads. Describe the sample space \(\Omega\). What is the probability that exactly k tosses are required?
Question 2: Let \(X_1,...,X_n \sim \text{Uniform(0,1)}\) and let \(Y_n = \max{X_1,...,X_n}\), what is \(E(Y_n)\) ?
Question 3: 2 players go in 2 different rooms where they each toss a coin simultanously. Each player then has to guess the other player’s toss outcome. The players can discuss their strategy beforehand, but cannot communicate once they enter their designated rooms. If both guessed wrong, they both get 0, if one or both correclty guessed the other players’ toss outcome then both win a payoff of 1. Find the optimal strategy and the associated expected payoff per player (hint, it is strictly higher than \(0.75\)).
Computer Question
Download psid data
Get the prepared data constructed from the PSID from Blundell,
Pistaferri and Saporta. To load this data you will need to install
the package readstata13. You can do that by running
install.packages('readstata13').
then you can load the data
require(readstata13)## Loading required package: readstata13 require(data.table)## Loading required package: data.table data = data.table(read.dta13("../data/data4estimation.dta"))we start by computing the wage residuals
data[, lwr := log_y] # we use raw wages, we could also use the residual from a regression on age, gender, etc...
# extract one wage per individual
Y = data[!is.na(lwr), list(lwr = lwr[1] ), person][,lwr]
hist(Y)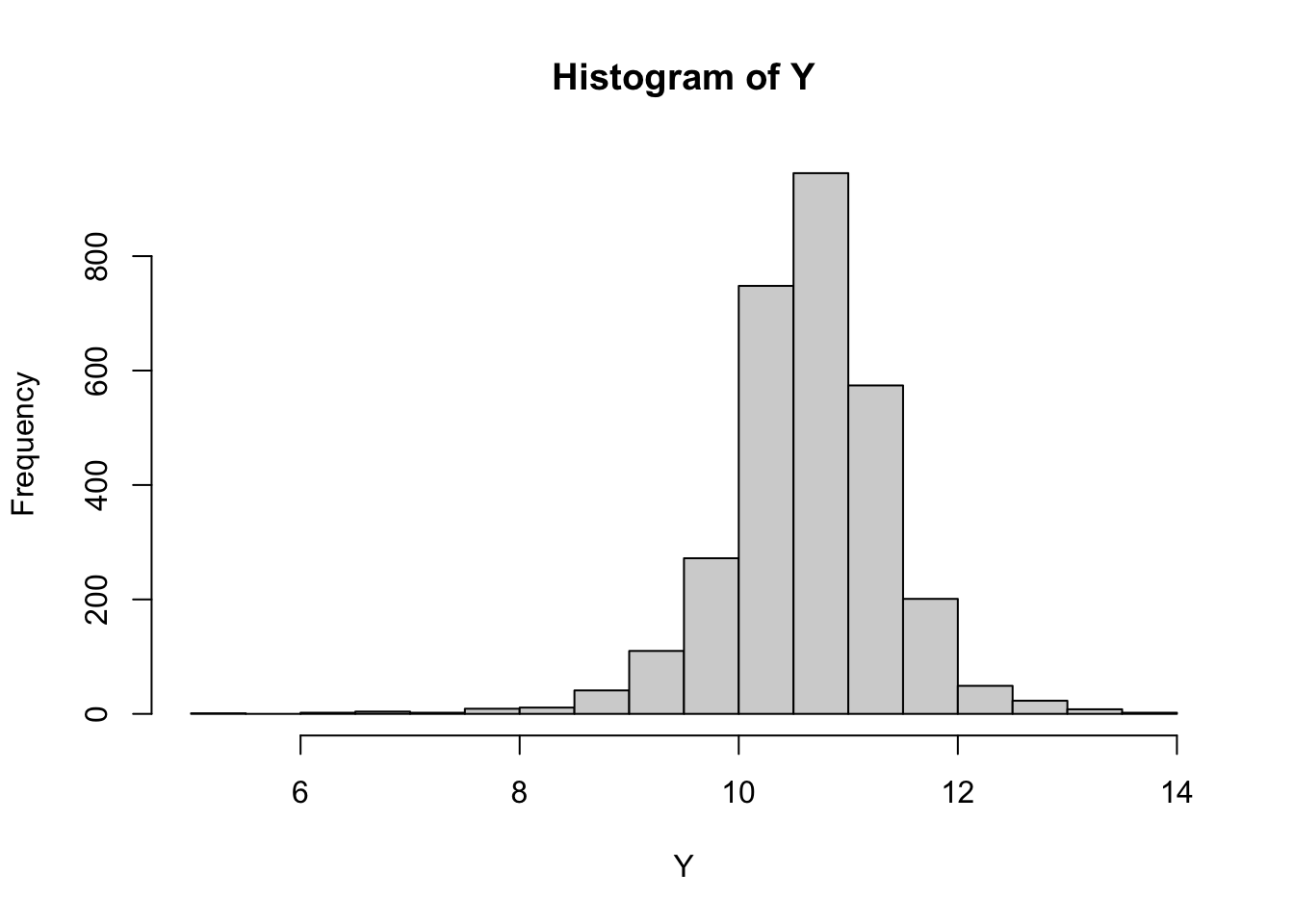
qqnorm(Y)
At this point we notice that the distribution of log wages is not a normal distribution. Never the less we want to form a confidence interval on the mean log wage in the population. The central limit theorem tells us how this will be distributed asymptotically.
Distribution of the mean
Call \(F(Y)\) the distribution of wages we recovered from the data. We are interested in constructing the distribution of the average of \(n\) draws from this distribution. for each \(n \leq N\) we will construct random samples from \(F(Y)\) simply by drawing with replacement from the wages we have in our data.
Question 4: Write a function that draws \(n\) wages from the data, and then computes its mean. For each value of \(n\) in \((2,5,10,25,50,100,150,200,500,1000,2000)\), use your function to generate 500 replications.
Question 5: For each value of \(n\) compute the quantiles accross replications and compare them to the quantile of normal distribution. Plot this function on the same graph using ggplot, and show that as \(n\) grows, the distribution approches the Normal distribution (recenter and rescale the means within each \(n\)).